
【ChatGLM3】部署教程
模型介绍
ChatGLM3 是智谱AI和清华大学 KEG实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K
硬件环境
📌
Int4 版本 ChatGLM3-6B最低配置要求:
内存:>= 8GB 显存: >= 5GB(1060 6GB,2060 6GB)
FP16 版本ChatGLM3-6B最低配置要求:
内存:>= 16GB 显存: >= 13GB(4080 16GB)
默认情况下,模型以FP16精度加载,所以平台中的V100、3090、4090均符合要求,这里我们选择平台中的4090进行使用
一、云部署操作指导
1、星海AI-GPU平台启动ChatGLM3-6B
星海AI-GPU平台内提供的GPU均满足ChatGLM3-6B运行需求,可任意选择GPU创建实例
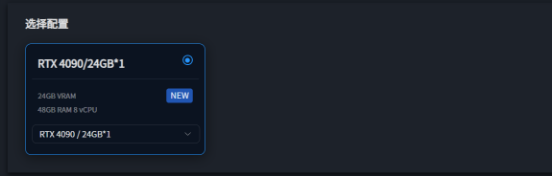

选择镜像市场
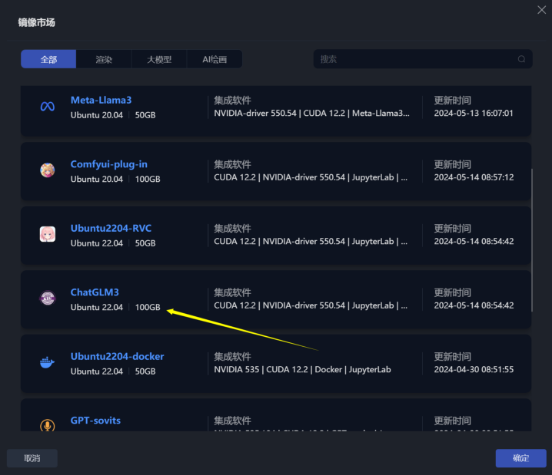
选择ChatGLM3
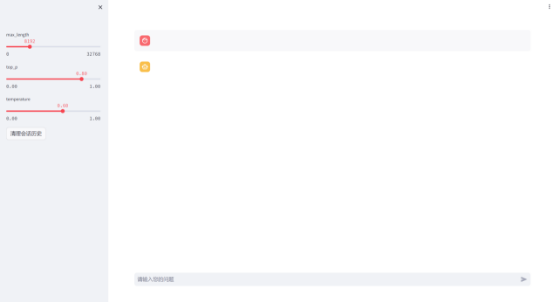
创建成功后点击应用中的ChatGLM3,即可进入到应用中,对话界面如下图所示:
二、本地操作指导
1、部署模型
在终端执行以下命令:
bash /root/str.sh第一次执行可能需要等待 2-3 分钟,但之后的启动只需 2-3 秒
运行完后会自动运行模型,可以直接和glm3交互:

2、微调模型
确保模型当前已停止运行,防止显存占用影响微调过程。
在左边的操作界面,去到ChatGLM3/finetune_chatmodel_demo路径下。在这里,你会找到一个名为formatted_data的文件夹,用于存放数据集。
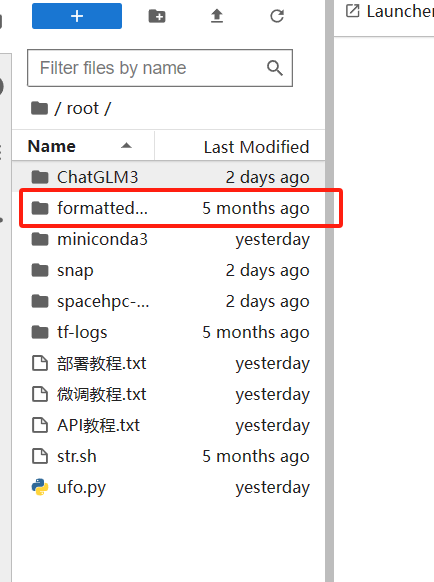
里面有一个advertise_gen.jsonl文件,这个就是我放的数据集。
你可以将该数据集替换为你自己的。确保新数据集的格式和文件名与原文件一致。
数据集应该遵循以下格式:
{"prompt": "我喜欢你", "response": "你是个好人"}
{"prompt": "我想做个好人, "response": "对不起,我是警察"}
回到ChatGLM3/finetune_chatmodel_demo路径下,打开finetune_pt.sh配置文件。 关注参数 MAX_STEP,这决定了训练的步数。例如,MAX_STEP=100 表示训练将在100步后结束。参数SAVE_INTERVAL是多少步保存一次,这里我设置成了50,根据你的需求调整这个数值,并保存。
修改好后在终端运行以下命令开始训练:
bash /root/ChatGLM3/finetune_chatmodel_demo/finetune_pt.sh当训练进度条全部完成后,回到ChatGLM3/finetune_chatmodel_demo路径下,打开"一键启动.py"文件。
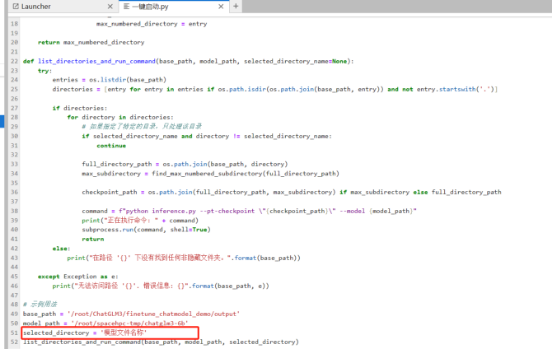
翻到最下面倒数第二行:selected_directory = \'模型文件名称\'
其中这个模型文件名称就是你刚刚微调好的模型名称,这个模型在这个路径下:ChatGLM3/finetune_chatmodel_demo/output 类似这样:model_170123 你把它复制下来
然后粘贴到红圈位置上然后保存就可以了。
最后在终端执行以下命令:
bash /root/ChatGLM3/finetune_chatmodel_demo/run.sh这将允许你与微调后的模型进行对话。
3、API部署
确保已经模型部署。不然无法进行API调用工作,以及确保模型当前停止运行,以防显存占用
首先打开两个终端:
在第一个终端中输入以下命令:
bash /root/ChatGLM3/openai_api_demo/one.sh等待终端进度条跑完,并出现输出提示:
http://0.0.0.0后,进行下一步。

在第二个终端中输入以下命令:
bash /root/ChatGLM3/openai_api_demo/two.sh这一步骤完成后,你将看到一个关于减肥的内容。


同时第一个终端反馈的内容
你可以打开ChatGLM3/openai_api_demo路径下的openai_api_request.py文件,在下面修改最后一块的content后面的内容。
也可以使用我写的调用代码,这样更方便,而且可以连续对话
python /root/ChatGLM3/openai_api_demo/new_api.py同样的,你可以修改模型的回复口吻。在ChatGLM3/openai_api_demo路径下打开new_api.py用刚刚一样的方法修改就行了
4、本地web界面部署
创建SSH隧道将远程服务映射到本地端口后即可使用ChatGLM3web功能
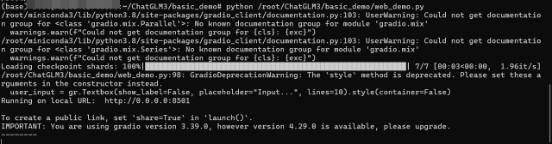
执行python /root/ChatGLM3/basic_demo/web_demo.py,成功运行服务后终端出现如下界面,出现
http://0.0.0.0:8501后,进行下一步
打开另一个新的终端或命令提示符,直接执行SSH命令
ssh -CNg -L 8888:localhost:8501 root@your-server-ip -p 22命令详解:
远程服务器的IP地址是your-server-ip。
你在远程服务器上的用户名是root。
远程服务器端口为22
远程服务器上ChatGLM3web运行的端口是8501。
你想要将此服务映射到本地机器的8888端口。
输入命令执行后,保持当前状态即正常运行

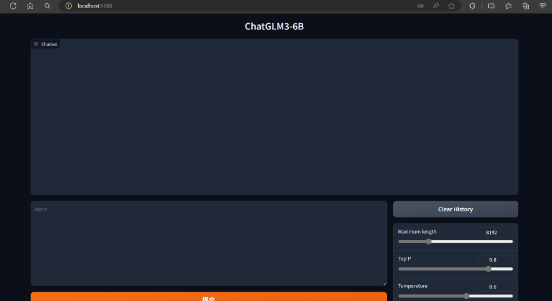
现在,只要SSH隧道保持开启(未关闭当前终端),你就可以在本地浏览器或其他客户端中通过访问
http://localhost:8888来使用远程的web界面。
社区客服:
